1.3. NumPy/SciPyを用いた実験データ解析¶
NumPy/SciPyを使う準備ができましたので,実際にプラズマ実験で得られたデータに対して解析をしてみましょう. ここでは,東京大学が所有する磁気圏型プラズマ装置RT-1 [RT-1] において得られた2視線のマイクロ波干渉計のデータを例にします. なお,今回解析対象とする実験では,変化が分かりやすいように時刻 t = 2.0 secに5 msec間のガスパフ入射を行っています.
なお、今回の記事で紹介する計測データには https://github.com/PlasmaLib/python_tutorial/tree/master/data からアクセスできます。 ぜひ自身のPCにダウンロードして、実際に手を動かして操作感を感じていただければと思います。
1.3.1. 実験データの読み込み¶
まずは実験データを読み込んでNumPyの配列を生成します.
NumPyではファイル形式にバイナリとテキストを選びファイルの読み書きを行うことができますが,ここでは np.loadtxt を使用してテキスト形式で保存されている実験データを読み込んでみます.
In [1]: IF = np.loadtxt("data/IF_20170608_74_raw.txt", delimiter=',')
NumPyにおけるテキスト形式での読み書きには,以下の特徴があります.
- 他のアプリケーションと互換性のある.dat, .csv, .txt形式のファイルの読み書きができる
- 保存できる配列の次元は2次元まで
なお,NumPyではテキスト形式以外にも,バイナリ形式の読み書きにも対応しています.
バイナリ形式の読み書きには, np.load , np.save , np.savez , np.savez_compressed を使います.
これらの関数は3次元以上のndarray配列も効率的にそのまま保存できますが,扱うファイル形式(.pickle, .npz, .npy)に他のアプリケーションとの互換性が殆どないことに注意が必要です.
バイナリ形式での読み書きに関する詳細は,公式HP [IO] を参照して下さい.
読み込んだデータの確認のため, Pythonで広く用いられるグラフ描写ライブラリであるMatplotlibを使って,グラフに表示してみます. Matplotlibの詳細は次章に譲るとして,ここでは以下のようにMatplotlibを読み込んでおきます.
In [2]: import matplotlib.pyplot as plt
In [3]: plt.plot(IF)
Out[3]:
[<matplotlib.lines.Line2D at 0x7f58ff27b4e0>,
<matplotlib.lines.Line2D at 0x7f58ff27b2b0>]
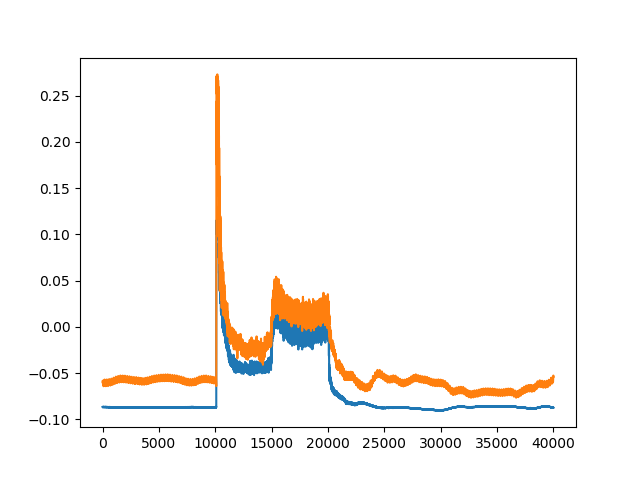
1.3.2. 配列の生成¶
次に,上図の時間軸を表示するための配列変数を作成します.
時間軸のような等差数列の生成には, np.arange や np.linespace を使用します.
なお,RT-1のマイクロ波干渉計では,時刻 t = 0.5 secから t = 4.5 secまで,サンプル周波数10 kHzでデータ収集を行っています.
In [4]: sampling_time = 1.0e-4
In [5]: delay = 0.5
In [6]: time = np.arange(len(IF)) * sampling_time + delay
ここで,時間軸などの生成によく利用する np.arange と np.linspace の使い方を簡単に紹介します.
numpy.arange¶
np.arange は,連番や等差数列を生成します.
使い方はPythonの組み込み関数rangeと似ており,以下のように引数を取ります.
なお, [] で囲んだ引数は省略できるということを意味します.
arange([start,] stop, [step,] dtype=None)
start で指定した数から stop で指定した数まで, step 間隔の数字列を生成します.
第2引数 stop 以外は省略ができますが,第3引数 step を指定するときは同時に第1引数 start も設定する必要があります.
なお,第2引数 stop だけを指定した場合は,初項0で交差1の等差数列を要素とするndarrayを生成します.
numpy.linspace¶
np.linspace は等差数列を生成する関数です.
同様の関数として先程紹介した np.arange がありますが, np.linspace を使用すると指定した区間をN等分した配列を生成しているということが明確になります.
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
の形で使用し,生成する等差数列の始点と終点を start と stop で指定します.
第3引数 num で配列の長さを,第4引数 endpoint で終点を配列の要素として含むかどうかを指定します.
1.3.3. 配列の演算¶
データを読み込んで配列が生成できたところで,計測信号の較正値を適用して 干渉計の位相信号を密度の値に変換し,そこからオフセットを差し引きます.
NumPyではndarrayで表現した行列に対して,行列の和・積,逆行列の計算,行列式の計算,固有値計算などさまざまな計算を行うメソッドや関数が用意されています.
ここで,行列計算ではndarrayの + (和), - (差), * (積), / (除算), ** (べき乗), // (打ち切り除算), % (剰余)は要素同士の計算になるという点に注意が必要です.
行列積を計算するには, dot メソッドを使うか, @ 演算子(Python3.5以上かつNumPy1.10以上)を使う必要があります.
今回の例では,まず較正係数を適用して信号値を位相差の値に変換します.
In [7]: a1 = -0.005
In [8]: a2 = 0.000
In [9]: b1 = 0.135
In [10]: b2 = 0.300
In [11]: IF[:, 0] = np.arcsin((IF[:, 0]-a1)/b1)*180/np.pi
In [12]: IF[:, 1] = np.arcsin((IF[:, 1]-a2)/b2)*180/np.pi
次に,位相差を線積分密度の値に変換します.
In [13]: IF = IF*5.58/360
最後に,プラズマのない時間帯の値をオフセットとして差し引きます.
In [14]: IF -= np.mean(IF[:5000], axis=0)
始めに作成した時間軸の配列とともにグラフに表示してみます.
In [15]: plt.plot(time, IF[:, 0]);
In [16]: plt.plot(time, IF[:, 1]);
In [17]: plt.xlim(1.0, 3.0);
In [18]: plt.ylim(0.0, 2.0);
In [19]: plt.xlabel('Time [sec]');
In [20]: plt.ylabel('$\mathbf{n_eL [10^{17}m^{-2}]}$')
Out[20]: Text(0,0.5,'$\\mathbf{n_eL [10^{17}m^{-2}]}$')

上記で用いた IF[:5000] は,プラズマがない時間帯(5000番目までの)のデータを切り出しています.
このような処理を インデキシング(Indexing) と呼びます.
[] の中身の :5000 で配列IFの第0軸(この場合は時間方向に相当)の先頭から5000番目までの部分を示しています.
切り出した配列に対し np.mean では, axis でどの軸(axis)に沿って平均を求めていくのかを決めています.
今回は各視線ごとの平均値を求めることが目的のため, axis=0 として行方向,つまり列ごとの平均である1次元の2要素(視線1,視線2のデータ)のベクトルを求めています.
IF -= np.mean(IF[:5000], axis=0) は,元のデータから上記で求めた平均を差し引く操作です.
2次元データである IF と, np.mean によって求めた1次元配列との引き算は,
大きさが異なるため計算できないように思えます.
その後の処理の,較正係数の引き算,除算も同様です.
実はNumPy では,ブロードキャスティング(Broadcasting) と呼ばれる仕組みにより,
大きさを揃える操作を自動的に行っています.
インデキシング¶
上の例のようにNumPyでは,インデキシングという処理により, 配列の任意の要素・行・列を切り出すことができます. ただし,切り出し方によりコピーを生成するかビュー(参照)を生成するかという違いがありますので注意が必要です. 本講座の2章で紹介したように,Pythonのリストやタプルにも実装されているスライシング(Slicing)をndarrayに対して行うと,その部分配列がビューとして返ってきます. つまり,その部分配列はデータのコピーではなく,元の配列の一部を参照していることになります. そのため,部分配列に対する変更はオリジナルのndarrayを変更してしまいます.
試しに,1列目の干渉計のプラズマ着火前の信号を抜き出してみます.
In [21]: IF_slice = IF[:5000, 0]
IF_sliceの中身を0に変更してみます.
In [22]: IF_slice[:] = 0
In [23]: IF[:5000, 0]
Out[23]: array([ 0., 0., 0., ..., 0., 0., 0.])
この例では,配列IF_sliceはビューですので,元の配列IFに変更が反映されています.
他の配列指向の言語ではスライスのようなデータ片はコピーとして生成する仕様のものが多いため,このインデキシングの仕様に驚く方は多いと思います. NumPyは,大量のデータ処理を目的として開発されてきました. ビューを用いると元のデータのコピーがメモリ上に作成されないため, 特に大きな配列の操作に適しています [1] .
ブロードキャスティング¶
+-*/ 等の四則演算や,ユニバーサル関数を使ってndarray同士の演算を行う際に,異なるサイズの2つのndarrayを使って計算を行わなければならないことがあります.
こういった処理を簡単・効率的にに行うため,NumPyでは配列演算の拡張ルールであるブロードキャスティングを採用しています.
以下にブロードキャスティングの一例として,1次元配列と2次元配列の配列演算を紹介します(図1).
#1から12までの等差数列を作成し,形状を(4, 3)に変更する
In [24]: b = np.arange(1, 13, 1).reshape((4, 3))
In [25]: b
Out[25]:
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
In [26]: c = np.array([1, 2, 3])
In [27]: c.shape # cの形状(shape)を確認する
Out[27]: (3,)
In [28]: b + c
��������������Out[28]:
array([[ 2, 4, 6],
[ 5, 7, 9],
[ 8, 10, 12],
[11, 13, 15]])
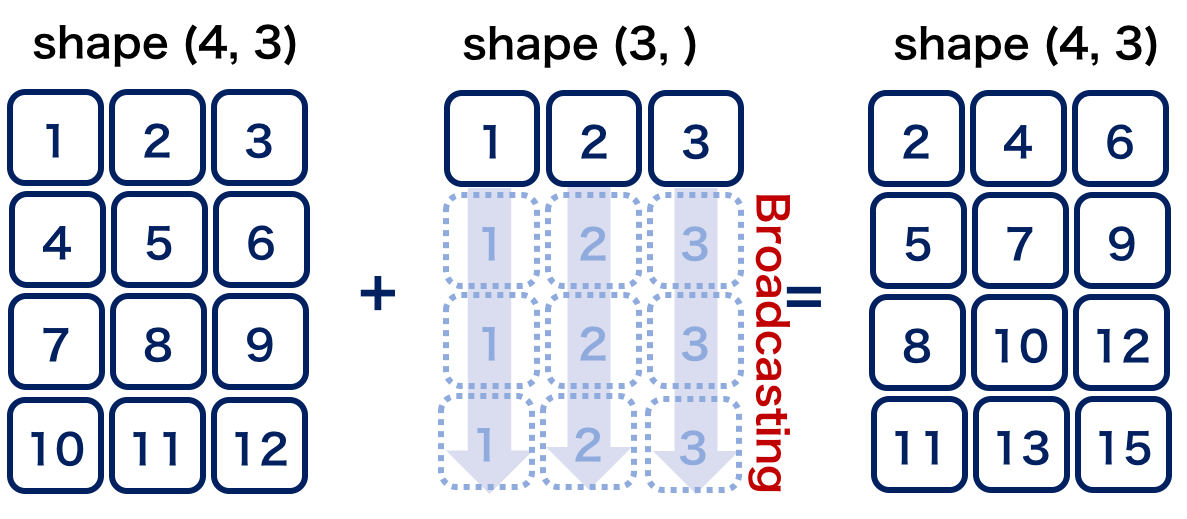
図 1.11 図1. ブロードキャスティングによる配列演算
NumPyには,配列の全要素に対して要素ごとに演算処理を行う,ユニバーサル関数が組み込まれています.
ユニバーサル関数はCやFortranで実装されており,かつ線形演算ではBLAS/LAPACKのおかげでC/C++と遜色のないほど高速に動作します.
例えば,exp 関数に配列を渡すことで,全要素に指数関数を適用した配列を生成することができます.
In [29]: np.exp(c)
Out[29]: array([ 2.71828183, 7.3890561 , 20.08553692])
このように,NumPyでは複数の配列要素に対して処理を一度に実行できます. こうすることで,ループ構造を用いるより圧倒的に高速に計算することができます.
Pythonのコードで良いパフォーマンスを得るには,以下の事が重要です.
- Pythonのループと条件分岐のロジックを,配列操作と真偽値の配列の操作に変換する
- 可能なときは必ずブロードキャストする
- 配列のビュー(スライシング)を用いてデータのコピーを防ぐ
- ユニバーサル関数を活用する
特に,Pyhonの言語仕様に慣れないうちはforループを多用しがちですが, これらに気をつけるとPythonでも高速で動作するプログラムを作ることができます.
1.3.4. SciPyを用いたデータ解析¶
時系列データの配列を作成することができたので,解析を行っていきましょう. 今回の例では, SciPyの信号処理に関するサブモジュールscipy.signalの中の関数spectrogramを用いて 上記のデータに短時間フーリエ変換を施して,プラズマの不安定性の有無を調べてみます.
In [30]: import scipy.signal as sig
In [31]: f, t, Pxx = sig.spectrogram(IF, axis=0, fs=1/sampling_time, window='hamming', nperseg=128, noverlap=64, mode='complex')
In [32]: plt.pcolormesh(t+0.5, f, np.log(np.abs(Pxx[:, 0]) + 1e-15));
In [33]: plt.xlim(1.5, 3.0);
In [34]: plt.xlabel('Time [sec]');
In [35]: plt.ylabel('Frequency [Hz]');
In [36]: plt.clim(-9, -6)
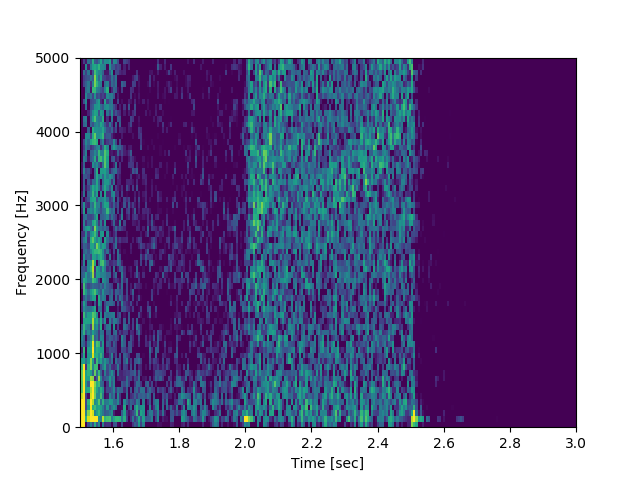
ここで, sig.spectrogram には,元のデータ IF のほか,
どの次元に対してフーリエ変換を施すかを axis オプションで,
サンプリング周波数や,窓関数を fs , window オプションで指定して渡しています.
t= 2.2 sec, 周波数 3〜4 kHz あたりに何か構造があるような気もします.
もう少しノイズを除去するために, 2つの干渉計信号のクロススペクトルを計算してみましょう. クロススペクトルは,以下の式で計算される量です.
ここで, <x> は x に関するサンプル平均を表します.ここでは移動平均で代用することにしましょう.
In [37]: def moving_average(x, N):
....: x = np.pad(x, ((0, 0), (N, 0)), mode='constant')
....: cumsum = np.cumsum(x, axis=1)
....: return (cumsum[:, N:] - cumsum[:, :-N]) / N
....:
# クロススペクトルを求める
In [38]: Pxx_run = moving_average(Pxx[:, 0] * np.conj(Pxx[:, 1]), 8)
In [39]: plt.pcolormesh(t+0.5, f, np.log(np.abs(Pxx_run)));
In [40]: plt.xlim(1.5, 3.0);
In [41]: plt.clim(-19, -15);
In [42]: plt.xlabel('Time [sec]');
In [43]: plt.ylabel('Frequency [Hz]')
Out[43]: Text(0,0.5,'Frequency [Hz]')
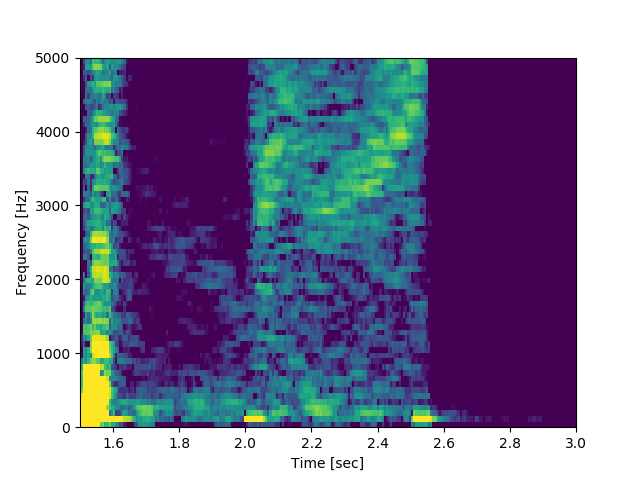
ここで,np.conj(x) は複素共役を求めるユニバーサル関数で,配列の要素ごとに適用されます.
移動平均を取る関数 moving_average の説明は省略しますが,
スライシングと累積和を用いることで効率よく計算しています.
上記操作により, 3〜4 kHz 付近の構造を可視化することができました.
このように,NumPy/SciPy の既存のツールを用いることで, スペクトル解析を簡単・高速に行うことができます. Matplotlib で描画することで,その結果をすぐに可視化しながら高速に解析を進めることができるでしょう.
1.3.5. 解析データの書き込み¶
最後に,物理量に変換した配列を時間軸と一緒にテキスト形式で保存します.
In [44]: np.savetxt('time_IF.txt', np.c_[time, IF], delimiter=',')
ここでは,配列の結合に np.c_ というオブジェクトを使用しています.
np.c_ は axis=1 の方向(2次元の場合は列方向)に,
np.r_ は axis=0 方向(2次元の場合は行方向)に配列を結合します.
どちらも関数ではなくオブジェクトなので,全て [] の中に配列や値を入れて操作していきます.
np.c_ や np.r_ について更に詳しく知りたい場合は,docstring等を参照して下さい [2] .
なお他にも,np.concatenate , np.hstack , np.vstack などの関数を用いても
配列の結合を行うことができます.
| [RT-1] | Z.Yoshida et al., Phys. Plasmas, 17, 112507 (2010). |
| [IO] | https://docs.scipy.org/doc/numpy-1.13.0/reference/routines.io.html |
| [1] | スライスをndarrayの実コピーとして生成する場合には,明示的に arr2d[1, 1:].copy() のようにします. |
| [2] | IPythonなどで np.r_? と呼び出してdocstringを確認することができます. |