2.2. pandas と xarray¶
Pythonの有名なデータ解析ライブラリに pandas [1] があります。 pandas は、汎用的なデータ解析に関するインターフェースを提供するものです。 その注目すべき特徴の1つが、座標付きのデータ(labeled data)をうまく扱うことができる点です。
例えば時系列データを扱うとき、時間データと計測値の2つを保持しておく必要が有ります。
ある時間領域を切り出す時は同じ操作を両データに適用する必要が有りますし、
またある時刻での計測値を知りたいときは、時間データから対応する要素番号を探しだし、
計測データに対してその要素番号を用いてアクセスすることが必要です。
これらの操作は前節で紹介した np.ndarray でももちろん可能ですが、
毎回各自がコーディングしていると時間がかかるだけでなく、ミスの元になります。
このようなデータ解析に必要な汎用的な操作をまとめてインターフェースとして提供しているのがpandasです (日付関連の操作や、欠損値に対する操作、複数のデータをまとめる操作など、他にも多様な便利機能がまとめられています)。 pandasはアンケート結果や株価の推移など、一般のデータ解析に広く用いられています。
一方でプラズマ計測データなど多くの物理データは、複数の座標軸を持ちます。 例えば、電子温度分布の時間変化データは、計測位置と時間という2つの軸を持つことになります。 ある時間における分布が知りたかったり、ある位置の温度の時間変化が知りたかったりします。 しかし pandas は1次元のデータ(表に表すことのできるデータ)しか扱うことができません。 xarray [2] [3] は、 pandas を多次元データに拡張したもので、地球科学研究分野から生まれたものです。 まだ新しいライブラリですが、 他種類の多次元データを扱うことの多いプラズマ研究でも有用だと思われますので、ここで紹介します。
| [1] | https://pandas.pydata.org/ |
| [2] | https://xarray.pydata.org/ |
| [3] | Hoyer, S. & Hamman, J., (2017). xarray: N-D labeled Arrays and Datasets in Python. Journal of Open Research Software. 5(1), p.10 |
2.2.1. xarray のインストール¶
Anaconda distribution を用いて Python 開発環境を整えた人は
conda install xarray
としてください。Native の Python を用いている人は
pip install xarray
とするとよいでしょう。
2.2.2. xarray の使い方¶
ここでは、実際のプラズマ実験データを使ってxarray の使い方を説明します。 核融合科学研究所で計測された トムソン散乱による電子温度・密度の結果を読み込みましょう。 ファイルの読み込みプログラムやいくつかの計測データの例を https://github.com/plasmalib/python_tutorial/data に用意しました。 これを data フォルダに保存して以下のように読み込みましょう。
In [1]: import xarray as xr # xarray は xr と省略するのが一般的なようです
In [2]: import sys
In [3]: sys.path.append('data')
In [4]: import eg # 読み込みプログラムも data/eg.py として保存しておいてください
In [5]: thomson = eg.load('data/thomson@115500.dat') # thomson データの読み込み
In [6]: print(thomson)
<xarray.Dataset>
Dimensions: (R: 140, Time: 246)
Coordinates:
* Time (Time) float64 0.0 33.0 66.0 100.0 133.0 166.0 200.0 233.0 ...
* R (R) float64 2.409e+03 2.436e+03 2.463e+03 2.49e+03 ...
ShotNo int64 115500
Data variables:
Te (Time, R) float64 90.0 20.0 22.0 83.0 46.0 54.0 27.0 0.0 ...
dTe (Time, R) float64 1e+05 1e+05 1e+05 1e+05 1e+05 1e+05 1e+05 ...
n_e (Time, R) float64 0.0 0.0 0.0 0.0 0.0 0.0 1.0 30.0 0.0 3.0 ...
dn_e (Time, R) float64 2.0 2.0 2.0 2.0 2.0 2.0 2.0 243.0 1.0 ...
laser (Time, R) float64 913.0 913.0 913.0 913.0 913.0 913.0 913.0 ...
lasernumber (Time, R) float64 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 ...
Attributes:
NAME: THOMSON
Date: 11/19/201215:24
まず、print 文を用いた時の出力が綺麗に整形されていることがわかります。
Dimensions の行に (R: 140, Time: 246) とあるのは、
含まれる変数は、2つの次元 Time と R に依存するということ、
それらの大きさがそれぞれ140、246であることを示しています。
Coordinates セクションには、それら軸の座標の値が表示されています。
LHDのThomson散乱では、電子温度や密度やその推定誤差などが得られますが、それらが
Data variables セクションに含まれています。
Data variables セクションの例えば Te の列には (Time, R) とありますが、
これはこの変数が Time と R に依存するということを示しています。
各 Coordinates や Data variables にアクセスするには、辞書型のように
['Te'] というようにすることでアクセスできます。
In [7]: thomson['Te']
Out[7]:
<xarray.DataArray 'Te' (Time: 246, R: 140)>
array([[ 90., 20., 22., ..., 0., 82., 1796.],
[ 6., 17., 10., ..., 19., 26., 13.],
[ 7., 0., 40., ..., 14., 6., 57.],
...,
[ 6., 133., 0., ..., 43., 40., 23.],
[ 10., 9., 48., ..., 70., 53., 58.],
[ 7., 39., 14., ..., 26., 0., 15.]])
Coordinates:
* Time (Time) float64 0.0 33.0 66.0 100.0 133.0 166.0 200.0 233.0 ...
* R (R) float64 2.409e+03 2.436e+03 2.463e+03 2.49e+03 2.517e+03 ...
ShotNo int64 115500
Attributes:
Unit: eV
このように1種類のデータを選んでも、同時に座標情報が付随していることがわかります。
ラベルを用いたインデクシング¶
Coordinate セクションに Time, R が表示されているように、このデータには座標情報も付属します。
.sel メソッドを用いることで、座標軸を元に要素を選択することができます。
In [8]: thomson.sel(Time=6800.0, method='nearest')
Out[8]:
<xarray.Dataset>
Dimensions: (R: 140)
Coordinates:
Time float64 6.8e+03
* R (R) float64 2.409e+03 2.436e+03 2.463e+03 2.49e+03 ...
ShotNo int64 115500
Data variables:
Te (R) float64 6.0 13.0 7.0 18.0 9.0 34.0 5.0 15.0 799.0 167.0 ...
dTe (R) float64 9.0 5.0 1e+05 29.0 0.0 12.0 1.0 2.0 134.0 0.0 ...
n_e (R) float64 -4.0 -13.0 1.0 -9.0 -3.257e+04 19.0 49.0 91.0 ...
dn_e (R) float64 2.0 1.0 2.0 3.0 121.0 3.0 5.0 6.0 1.0 59.0 8.0 ...
laser (R) float64 912.0 912.0 912.0 912.0 912.0 912.0 912.0 912.0 ...
lasernumber (R) float64 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 ...
Attributes:
NAME: THOMSON
Date: 11/19/201215:24
ここでは、 Time 軸が 6800.0 に最も近い計測値を取得しています。
Dimensions の行から Time が消えて (R: 140) だけになったことからもわかるように、
全ての計測値を一度にインデクシングしていることがわかります。
ある時刻の結果だけグラフに描きたい、ということもよくありますが、
その場合も、 .sel メソッドを用いることで1行で実現できます。
In [9]: plt.plot(thomson['R'], thomson['Te'].sel(Time=6800.0, method='nearest'))
Out[9]: [<matplotlib.lines.Line2D at 0x7f58ff3afda0>]
In [10]: plt.xlabel('$R$ (m)')
������������������������������������������������������Out[10]: Text(0.5,0,'$R$ (m)')
In [11]: plt.ylabel('$T_\mathrm{e}$ (eV)')
�������������������������������������������������������������������������������������Out[11]: Text(0,0.5,'$T_\\mathrm{e}$ (eV)')

座標名を利用した操作¶
xarray では、軸に名前が付いているので、データが格納されている配列の軸の順序
(1つ目の軸が Time 、2つ目の軸が R に対応している、など)を覚えておく必要がありません。
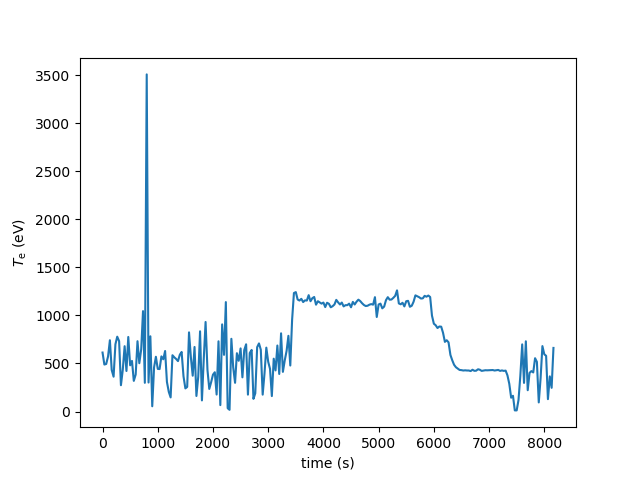
例えば、プラズマ中心での電子温度の時間変化が知りたいとしましょう。 ただし、ある一点の計測値のみを用いるとノイズが大きくなるので、 ある程度の範囲内でデータを平均するのがよいでしょう。
今回は、プラズマ中心付近の 3500 ~ 3800 mm での温度を平均することにしましょう。
まず、データに付属する軸情報から、この範囲内に収まるデータのみを切り出します。
上記と同様に sel メソッドを用いることができます。
# R = 3500.0 - 3800.0 間のデータを選択
In [12]: thomson_center = thomson.sel(R=slice(3500.0, 3800.0))
In [13]: thomson_center
Out[13]:
<xarray.Dataset>
Dimensions: (R: 17, Time: 246)
Coordinates:
* Time (Time) float64 0.0 33.0 66.0 100.0 133.0 166.0 200.0 233.0 ...
* R (R) float64 3.502e+03 3.521e+03 3.54e+03 3.559e+03 ...
ShotNo int64 115500
Data variables:
Te (Time, R) float64 2.099e+03 8.383e+03 1.446e+04 5.0 ...
dTe (Time, R) float64 1e+05 1e+05 2.882e+04 1e+05 1e+05 1e+05 ...
n_e (Time, R) float64 0.0 0.0 3.0 11.0 0.0 0.0 0.0 3.0 0.0 0.0 ...
dn_e (Time, R) float64 0.0 1.0 8.0 51.0 0.0 0.0 1.0 26.0 1.0 1.0 ...
laser (Time, R) float64 913.0 913.0 913.0 913.0 913.0 913.0 913.0 ...
lasernumber (Time, R) float64 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 ...
Attributes:
NAME: THOMSON
Date: 11/19/201215:24
このデータを大半径方向に平均することにしましょう。
平均操作には mean メソッドを用います。
引数として、2つの軸 (R, Time)のうち、どちらの方向に平均をとるかを指定します。
In [14]: thomson_center.mean(dim='R') # 'R' 方向の平均
Out[14]:
<xarray.Dataset>
Dimensions: (Time: 246)
Coordinates:
* Time (Time) float64 0.0 33.0 66.0 100.0 133.0 166.0 200.0 233.0 ...
Data variables:
Te (Time) float64 3.493e+03 4.575e+03 8.478e+03 834.7 ...
dTe (Time) float64 8.549e+04 1.951e+04 9.317e+03 7.085e+03 ...
n_e (Time) float64 1.0 1.474e+03 861.5 1.352e+03 668.2 373.5 ...
dn_e (Time) float64 5.647 12.18 12.12 16.76 10.59 9.647 9.118 ...
laser (Time) float64 913.0 914.0 910.0 912.0 909.0 912.0 912.0 ...
lasernumber (Time) float64 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 ...
In [15]: plt.plot(thomson_center['Time'], thomson_center['Te'].median(dim='R'))
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Out[15]: [<matplotlib.lines.Line2D at 0x7f58d7c2b5c0>]
In [16]: plt.xlabel('time (s)')
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Out[16]: Text(0.5,0,'time (s)')
In [17]: plt.ylabel('$T_\mathrm{e}$ (eV)')
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Out[17]: Text(0,0.5,'$T_\\mathrm{e}$ (eV)')
座標を用いた異種データの結合¶
異なる時間間隔で計測されたデータ間を結合したい時もあると思います。 例えば、トムソン散乱と干渉計による電子密度の計測結果を比べることを考えます。 ただし、トムソン散乱と干渉計では計測タイミングが異なるので直接は比較できません。 この場合に限らず、複数種のデータを扱う際はこのような操作が必須です。 pandas や xarray には簡便な方法が用意されています。
ここではまず、干渉計のデータを読み込みましょう。
同様に、 data ディレクトリ内にデータを用意しておいてください。
In [18]: fir = eg.load('data/firc@115500.dat') # 干渉計データの読み込み
In [19]: fir
Out[19]:
<xarray.Dataset>
Dimensions: (Time: 1311)
Coordinates:
* Time (Time) float64 0.1 0.11 0.12 0.13 0.14 0.15 0.16 0.17 0.18 ...
ShotNo int64 115500
Data variables:
nL(3669) (Time) float64 0.0001822 0.0001822 0.0001822 0.0001822 ...
nL(3759) (Time) float64 -0.003244 -0.003244 -0.003244 0.005867 ...
Attributes:
NAME: firc
Date: 11/19/201222:20
干渉計の計測時刻は (0.1, 0.11, ...) となっており、
トムソン散乱の計測時刻 (0.3, 0.33, ...) と異なることがわかります。
ここでは、トムソン散乱の計測時刻に最も近い計測時刻での干渉計のデータを集めてくることにしましょう。
そのためには reindex メソッドを利用できます。引数に、比較したい軸(今回は Time )とその比較対象、およびその方法を指定します。今回は最近傍のもの (nearest) を取得します。
# thomson の時刻が [ms]なので [s] に修正する。
In [20]: thomson['Time'] = thomson['Time'] * 0.001
# thomson の時刻に最も近い fir 計測結果を取得する。
In [21]: fir_selected = fir.reindex(Time=thomson['Time'], method='nearest')
In [22]: fir_selected
Out[22]:
<xarray.Dataset>
Dimensions: (Time: 246)
Coordinates:
* Time (Time) float64 0.0 0.033 0.066 0.1 0.133 0.166 0.2 0.233 0.266 ...
ShotNo int64 115500
Data variables:
nL(3669) (Time) float64 0.0001822 0.0001822 0.0001822 0.0001822 ...
nL(3759) (Time) float64 -0.003244 -0.003244 -0.003244 -0.003244 ...
Attributes:
NAME: firc
Date: 11/19/201222:20
これで両者の演算が可能になります。
その他の特徴¶
xarray は他にも様々な便利機能を備えています。
ここではこれらを説明する紙面の余裕がありませんが、 どれも広い分野のデータ解析に有用な機能となっています。 xarray の document ページ http://xarray.pydata.org をご参考ください
こういったライブラリが提供するツールは、 コーディングさえすればNumpyだけでも実現できます。 そのため、時間をかけてライブラリの使用法を習得しようというインセンティブが湧かないかもしれません。 しかし毎回自身でコーディングすることは、試行錯誤のスピードを低下させるだけでなく、 ケアレスミスも誘発します。
最初に使用法を覚える段階はまどろっこしく自身で作った方が早いように感じますが、 慣れてしまうとこのようなライブラリを用いる方が圧倒的に操作が楽に確実になります。 有用なツールの習得に時間をかけるのは、ちょっとした投資と言えるかもしれません。
| [5] | https://www.unidata.ucar.edu/software/netcdf/ |
| [6] | https://dask.pydata.org/en/latest/ |